Recentemente, o setor fiscal precisou validar e cadastrar diversas NCMs para que fossem exibidas corretamente no cadastro de cenários do Consinco.
O processo era totalmente manual, o que tomava muito tempo e abria margem para erros.
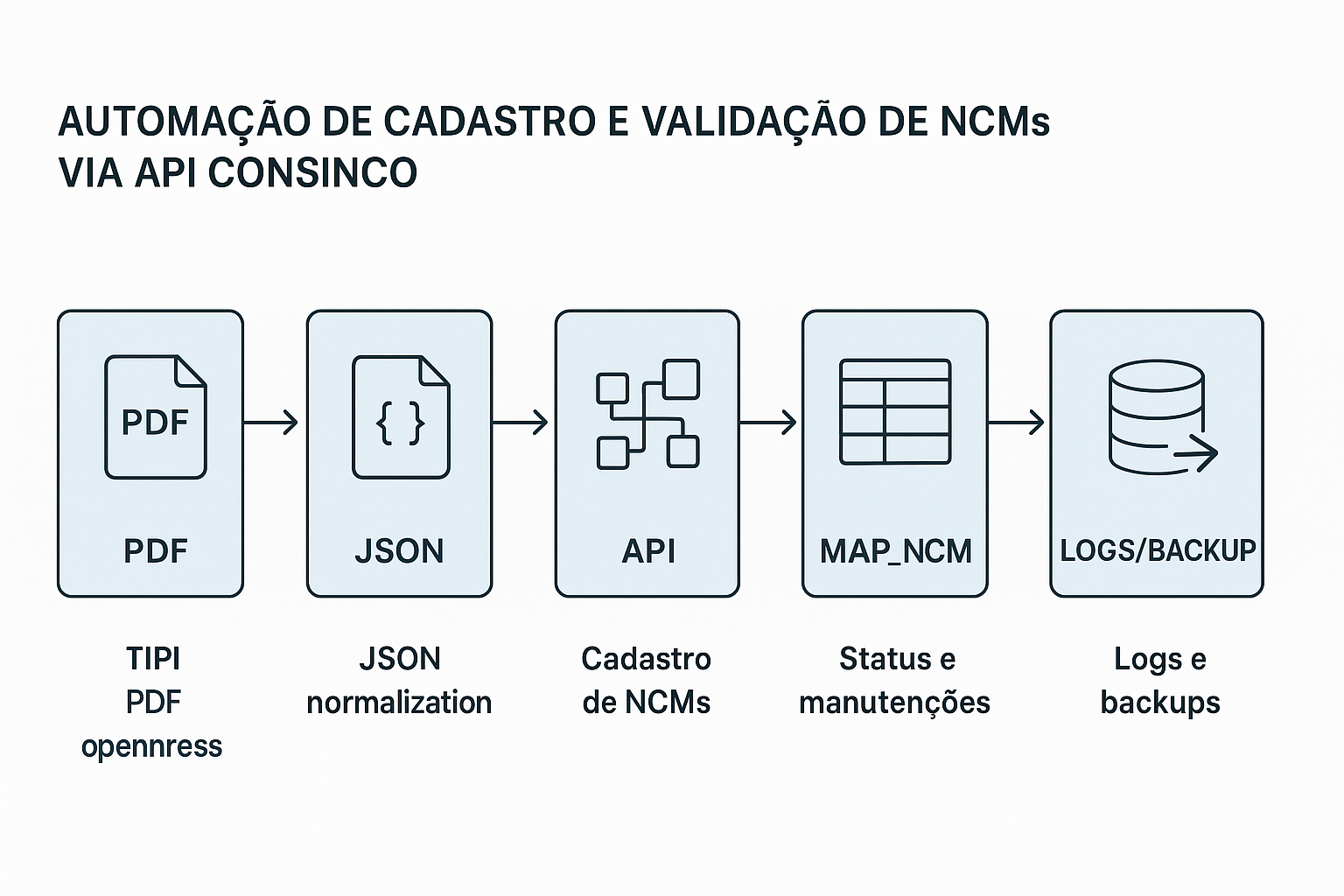
Para resolver isso, desenvolvi uma automação completa, que extrai as NCMs diretamente do PDF da TIPI, transforma os dados em JSON e faz o cadastro automático via API do Consinco, além de atualizar registros inconsistentes já existentes no MAP_NCM.
🧰 Ferramentas utilizadas
- Python 3.8+
- pdfplumber → extração das tabelas do PDF da TIPI
- pandas → limpeza, normalização e geração de JSON
- requests → integração com a API Consinco
- cx_Oracle → consultas e atualizações diretas no banco Oracle
- logging / CSV → logs e backups automáticos
📄 Etapa 1 – Extração da TIPI (PDF)
O primeiro passo foi ler o PDF oficial da TIPI (Tabela de Incidência do IPI) disponibilizada pela Receita Federal:
📥 Fonte oficial: https://www.gov.br/receitafederal/pt-br/acesso-a-informacao/legislacao/documentos-e-arquivos/tipi.pdf
Utilizei a biblioteca pdfplumber, que facilita a leitura de tabelas contidas em arquivos PDF.
import pdfplumber
import re
import pandas as pd
def extrair_tipi(pdf_path):
ncm_data = []
with pdfplumber.open(pdf_path) as pdf:
for page in pdf.pages:
text = page.extract_text()
linhas = text.split("\n")
for linha in linhas:
match = re.match(r"^(\d{8})\s+(.+)$", linha)
if match:
codigo, descricao = match.groups()
ncm_data.append({"codigo": codigo, "descricao": descricao})
return pd.DataFrame(ncm_data)
Esse código percorre cada página, identifica NCMs válidas (8 dígitos) e monta um DataFrame estruturado.
🔄 Etapa 2 – Normalização e geração de JSON
Após a extração, fiz o tratamento dos dados e gerei um arquivo JSON pronto para integração.
df = extrair_tipi("TIPI_2024.pdf")
df["descReduzida"] = df["descricao"].str[:50]
json_data = df.to_dict(orient="records")
Isso garante que a descrição seja compatível com o limite de caracteres aceito pela API.
🌐 Etapa 3 – Integração com a API Consinco
Com os dados normalizados, a automação realiza chamadas POST para o endpoint de cadastro de NCM.
A API utilizada é a do módulo Cadastros Estruturais, que pode ser explorada diretamente pelo Swagger local:
🔗 API Consinco Swagger: http://localhost:8343/CadastrosEstruturaisApi/swagger/index.html
import requests
API_URL = "http://localhost:8343/CadastrosEstruturaisApi/api/Ncm"
headers = {"Content-Type": "application/json"}
for item in json_data:
payload = {
"ncm": item["codigo"],
"descricao": item["descricao"],
"descReduzida": item["descReduzida"]
}
response = requests.post(API_URL, json=payload, headers=headers)
print(f"{item['codigo']} -> {response.status_code}")
O script executa em modo batch, tratando duplicidades e validando o retorno da API antes de prosseguir com o próximo item.
🧮 Etapa 4 – Atualização e manutenção do MAP_NCM
Além de cadastrar novas NCMs, o processo identifica e corrige registros já existentes, mas que estavam com status vazio ou inconsistentes.
import cx_Oracle
conn = cx_Oracle.connect("user", "password", "ip:1521/db")
cur = conn.cursor()
query = """
UPDATE MAP_NCM
SET STATUS = 'A'
WHERE STATUS IS NULL
"""
cur.execute(query)
conn.commit()
Antes de qualquer modificação, o sistema gera um backup CSV completo da tabela MAP_NCM, garantindo rastreabilidade e rollback seguro se necessário.
📦 Etapa 5 – Backups e logs automáticos
Cada execução gera automaticamente:
- Um CSV com a versão anterior do
MAP_NCM - Um JSON com todos os payloads enviados à API
- Um log detalhado com data, hora e retorno da API
import logging
from datetime import datetime
logging.basicConfig(filename=f"logs/ncm_{datetime.now():%Y%m%d}.log",
level=logging.INFO,
format="%(asctime)s - %(message)s")
logging.info("Processo iniciado com %d NCMs", len(json_data))
Esses logs permitem auditoria total de tudo o que foi processado, incluindo tempo de execução, erros e respostas do servidor.
⚙️ Etapa 6 – Validação e auditoria final
Após o cadastro, um segundo script valida as NCMs recém-criadas e confirma se o cenário de integração do Consinco está refletindo as mudanças corretamente.
df_verificacao = pd.read_sql("SELECT NCM, STATUS FROM MAP_NCM", conn)
novos_registros = df_verificacao[df_verificacao["STATUS"] == "A"]
print(f"{len(novos_registros)} NCMs ativas após a atualização.")
📊 Resultados obtidos
- 1.882 NCMs cadastradas automaticamente
- 86 NCMs corrigidas com status inconsistentes
- Economia de tempo: cerca de 32 horas/mês poupadas
- Rastreabilidade total por meio de logs e backups
- Execução escalável, podendo rodar em modo agendado via n8n
💡 Conclusão
Essa automação substituiu um processo manual e repetitivo por um pipeline robusto e automatizado, trazendo eficiência, segurança e transparência ao controle fiscal.
Ao combinar Python, API REST e integração com o Oracle, foi possível criar um fluxo totalmente rastreável e fácil de manter — e que pode ser facilmente expandido para outros módulos do Consinco, como produtos, fornecedores ou parâmetros fiscais.